
According to the slides from a 2023 Linux Storage, Filesystem, Memory-Management and BPF Summit talk, guests operating through the netkit device (which was called "meta" at that time) are able to attain TCP data-transmission rates that are just as high as can be had by running directly on the host. The performance penalty for running within a guest has, in other words, been entirely removed.
Monday, November 27. 2023
More eBPF
Saturday, May 29. 2021
Re: [PATCH bpf-next] xsk: support AF_PACKET (XDP)
> In xsk mode, users cannot use AF_PACKET(tcpdump) to observe the current > rx/tx data packets. This feature is very important in many cases. So > this patch allows AF_PACKET to obtain xsk packages.
You can use xdpdump to dump the packets from the XDP program before it gets redirected into the XSK: https://github.com/xdp-project/xdp-tools/tree/master/xdp-dump
Doens't currently work on egress, but if/when we get a proper TX hook that should be doable as well.
Wiring up XSK to AF_PACKET sounds a bit nonsensical: XSK is already a transport to userspace, why would you need a second one?
Yes, it is rather cool (credit to Eelco). Notice the extra info you can capture from 'exit', like XDP return codes, if_index, rx_queue. The tool uses the perf ring-buffer to send/copy data to userspace. This is actually surprisingly fast, but I still think AF_XDP will be faster (but it usually 'steals' the packet).
Another (crazy?) idea is to extend this (and xdpdump), is to leverage Hangbin's recent XDP_REDIRECT extension e624d4ed4aa8 ("xdp: Extend xdp_redirect_map with broadcast support"). We now have a xdp_redirect_map flag BPF_F_BROADCAST, what if we create a BPF_F_CLONE_PASS flag?
The semantic meaning of BPF_F_CLONE_PASS flag is to copy/clone the packet for the specified map target index (e.g AF_XDP map), but afterwards it does like veth/cpumap and creates an SKB from the xdp_frame (see __xdp_build_skb_from_frame()) and send to netstack. (Feel free to kick me if this doesn't make any sense)
> This would be a smooth way to implement clone support for AF_XDP. If > we had this and someone added AF_XDP support to libpcap, we could both > capture AF_XDP traffic with tcpdump (using this clone functionality in > the XDP program) and speed up tcpdump for dumping traffic destined for > regular sockets. Would that solve your use case Xuan? Note that I have > not looked into the BPF_F_CLONE_PASS code, so do not know at this > point what it would take to support this for XSKMAPs.
Recently also ended up with something similar for our XDP LB to record pcaps [0]My question is.. tcpdump doesn't really care where the packet data comes from, so why not extending libpcap's Linux-related internals to either capture from perf RB or BPF ringbuf rather than AF_PACKET sockets? Cloning is slow, and if you need to end up creating an skb which is then cloned once again inside AF_PACKET it's even worse. Just relying and reading out, say, perf RB you don't need any clones at all.
Anyway, xdpdump does have a "pipe pcap to stdout" feature so you can do `xdpdump | tcpdump` and get the interactive output; and it will also save pcap information to disk, of course (using pcap-ng so it can also save metadata like XDP program name and return code).
Thursday, October 22. 2020
DP based BGP peering Router
Sunday, August 16. 2020
eBPF Tools
Friday, August 16. 2019
eBPF - Little Things
Sunday, May 5. 2019
eBPF Basics
Monday, December 24. 2018
Late To The Party - Better Late Than Never
I was happily building some code to filter and manage traffic in Open vSwitch via C++ communicating via the OpenFlow interface. Then, ... well, I realized I was missing some things. In OVS's documentation, much of it uses the command line tools to inject the rules. Some of those examples show automatic mac swaps and such. hmm, Nicera extensions but not in the openflow specification. Which means changing code to interface to other api bind points of OVS.
I had also written some code to interface to the OVSDB so I could list interfaces, detect changes, and obtain statistics.
In stepping back and thinking about this, I came across a youtube video on youtube:
which talks about Stratum and Next-Gen SDN. I wasn't so interested in the Stratum concept in as much as I was interested in the p4.org concept of writing code to filter packets.
From a Linux network stack perspective, a little closer to home, there is eBGP and XDP. The best diagram I've seen of XDP and eBGP hook points is on page 3 of 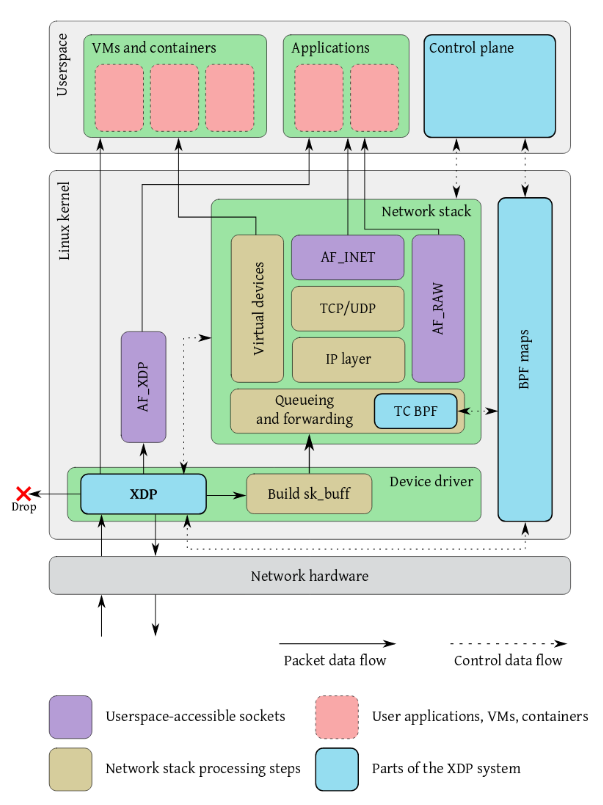 The eXpress Data Path: Fast Programmable Packet Processing inthe Operating System Kernel which was presented at
2018 SigComm CoNEXT Conference. As an aside, another interesting paper there is "
Leveraging eBPF for programmable network functions with IPv6 Segment Routing".
The eXpress Data Path: Fast Programmable Packet Processing inthe Operating System Kernel which was presented at
2018 SigComm CoNEXT Conference. As an aside, another interesting paper there is "
Leveraging eBPF for programmable network functions with IPv6 Segment Routing".
Other references:
- BPF and XDP Reference Guide
- BPF Compiler Collection (BCC)
- Linux Plumbers Conference 2018 BPF Microconference
- Linux Plumbers Conference 2018 Networking Track
- Linux Bridge, l2-overlays, E-VPN!
- Scaling bridge forwarding database
- Lifetime of BPF objects
- P4-16 Language Specification
- net: add bpfilter
- AF_XDP
- Linux Network Programming with P4
- bpf - perform a command on an extended BPF map or program
- BPF - BPF programmable classifier and actions for ingress/egress queueing disciplines
- 7 tools for analyzing performance in Linux with bcc/BPF - gethostlatency, tcplife, biolatency, opensnoop, execsnoop, ...
In Debian with Kernel "4.19.0-1-amd64 #1 SMP Debian 4.19.12-1 (2018-12-22)", the following are set:
# grep -i bpf /boot/config-4.19.0-1-amd64 CONFIG_CGROUP_BPF=y CONFIG_BPF=y CONFIG_BPF_SYSCALL=y # CONFIG_BPF_JIT_ALWAYS_ON is not set CONFIG_IPV6_SEG6_BPF=y CONFIG_NETFILTER_XT_MATCH_BPF=m # CONFIG_BPFILTER is not set CONFIG_NET_CLS_BPF=m CONFIG_NET_ACT_BPF=m CONFIG_BPF_JIT=y # CONFIG_BPF_STREAM_PARSER is not set CONFIG_LWTUNNEL_BPF=y CONFIG_HAVE_EBPF_JIT=y CONFIG_BPF_EVENTS=y # CONFIG_BPF_KPROBE_OVERRIDE is not set CONFIG_TEST_BPF=m # grep -i xdp /boot/config-4.19.0-1-amd64 # CONFIG_XDP_SOCKETS is not set
Install the the BPF Compiler Tools with:
apt install libbpfcc libbpfcc-dev bpfcc-tools python-bpfcc
bcc header files are in '/usr/include/bcc/'. Many tools with suffic 'bpfcc' are installed in /usr/sbin. There is a man page for each. Many many examples can be found in /usr/share/doc/bpfcc-tools/examples/doc/.
7 tools for analyzing performance in Linux with bcc/BPF covers execsnoop, opensnoop, xfsslower, biolatency, tcplife, gethostlatency and trace. The article also refers to bcc Python Developer Tutorial. Also referenced was bpftrace. A better page referencing these tools is Linux Extended BPF (eBPF) Tracing Tools. eBPF: One Small Step is an early Brendan Gregg article on eBPF tracing.
Going even deeper into the woods, another tool referenced includes SystemTap which has a Debian Package.
The BCC has a reference guide. Most of the preceding has to do with tracing. Now to get to packet manipulation.
For compiling, some packages:
apt install clang llvm clang-7-doc ncurses-doc libomp-7-doc llvm-7-doc
Some items from Making the Kernel’s Networking Data Path Programmable with BPF and XDP:
- 11 64bit registers, 32bit subregisters, up to 512bytes stack
- Instructions 64bit wide, max 4096 per program
- BPF calling convention for helpers allows for efficient mapping: a) R0 →return value from helper call, b) R1 - R5 →argument registers for helper call, c) R6 - R9 → callee saved, preserved on helper call
- /proc/kallsyms exposure of JIT image as symbol for stack traces
- Since LLVM 3.7: clang -O2 -target bpf -c foo.c -o foo.o
- To show ability: llc --version | grep bpf
- Assembler output through -S supported
- llvm-objdump for disassembler and code annotations (via DWARF)
- C example walkthrough: tools/testing/selftests/bpf/testl_4lb.c
- when attaching to generic XDP kernel driver via iproute2: ip link set dev eno1 xdpgeneric obj prog.o
2019/05/04 - Hacker News had a reference to CloudFlare where they discussed eBPF can't count?! - an article with references on how to debug eBPF code.

